

Warum eine lokale Spracherkennung?
Der größte Vorteil einer lokalen Installation von OpenAI Whisper liegt auf der Hand:
Weder Ihre Stimme noch ihre Audiodaten verlassen den eigenen Rechner!
Gerade bei sensiblen Inhalten – Interviews, Forschung, Unterricht, internen Meetings oder kreativen Texten – ist Datenschutz kein „Nice-to-have“, sondern möglicherweise eine gesetzliche Anforderung. Eine lokale Whisper-Installation bedeutet:
- Volle Datenhoheit (keine Cloud, keine API-Uploads)
- Offline-Fähigkeit
- Reproduzierbare Ergebnisse
- Keine laufenden Kosten pro Token bzw. Audiominute
- Kontrolle über die KI-Modellgröße und Qualität
- Lauffähig auch auch leistungsschwachen Computern wie dem Raspberry Pi 5
Im Gegensatz zu vielen Cloud-Diensten bleibt Whisper vollständig transparent: Man weiß, welches KI-Modell läuft, wie lange es rechnet und wo die Ergebnisse gespeichert werden.
Bequemlichkeit oder individueller Datenschutz?
ChatGPT bietet im Audiobereich zwei sehr bequeme Arten der Interaktion an:

Diktieren bedeutet, den Prompt durch Sprechen zu befüllen, aber den Text zusätzlich per Tastatur abändern zu können. Der Audiomodus führt dagegen zu einem direkten Dialog, der nur durch einen Audiomitschnitt gespeichert werden kann. In ChatGPT-Diktieren-Audiomodus.pdf. beschreibt ChatGPT 5.2 diese Funktionen recht anschaulich. Was allerdings mit den übertragenen Sprachdaten geschieht, bleibt unklar.

Und auch Ameca, ein humanoider Roboter, mit dem man im Deutschen Museum Nürnberg (Zukunftsmuseum) wunderbar interagieren kann, bleibt in dieser Hinsicht schweigsam.
Sprachsynthese (TTS = Text to Speech) wird wirksam, wenn Ameca spricht, und eine Spracherkennung (STT = Speech to Text) erfolgt, wenn Ameca zuhört. Ob Ihre Stimme dabei in die USA übertragen wird, wollte Ameca mir nicht verraten.
Künstlich generierte Stimmen sind übrigens an ganz kleinen Auffälligkeiten im MEL-Spektrum der Audiodatei erkennbar, das man sich mit Audacity anzeigen lassen kann.
Sprachsynthese und Spracherkennung
Ameca hat eine Verbindung zu ChatGPT und wie bei „Audiomodus verwenden“ auf der OpenAI-Webseite können Sie bei der Interaktion zwischen Mensch und Maschine Gefühle empfinden. Ameca hat eine fest vorgegebene Stimme, fasziniert aber durch Mimik und Robotik. Dem heimischen ChatGPT kann man dagegen selbst eine Stimmlage zuordnen und die Vorlesefunktion (Lautsprechersymbol) funktioniert auch ganz gut. Als „Platzhirsch“ im Bereich Sprachsynthese gilt hingegen ElevenLabs. Während die Zerlegung von Sprachsignalen in Phoneme der vor 20 Jahren übliche Standard war, sind die LLMs (Large Language Models) auch in diesem Bereich dominant geworden, und haben das umständliche Trainieren mit der eigenen Stimme (vor der Spracherkennung) obsolet gemacht. In der Bezahlversion genügt ElevenLabs eine Stimmprobe von einer Minute zur Generierung beliebig vieler gesprochener Texte.
OpenAI Whisper installieren
Im Downloadbereich finden Sie in Kürze alle notwendigen Dateien zur Installation von Whisper auf ihrem PC, wobei folgende Dateien verwendbar sind:
- inst_whisper.bat (für Windows10/11)
- inst_whisper.sh (für Linux/Raspberry Pi)
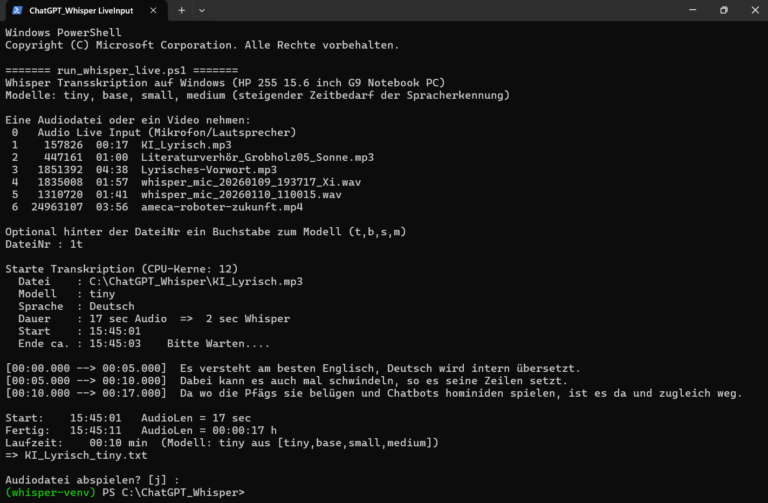
Arbeiten mit run_whisper_live.ps1
Der Workflow ist bewusst einfach gehalten:
Einlesen von
.mp3und.mp4DateienZusätzlich ein Live-Modus für direkte Mikrofonaufnahme
Modellauswahl über Buchstaben-Anhang
Beispiele zur Eingabe bei DateiNr:
1t → Datei 1 mit Modell tiny(im Screenshot verwendet)
2b → Datei 2 mit Modell base
3s → Datei 3 mit Modell small
Das erlaubt ein schnelles Experimentieren mit unterschiedlichen Modellen (von tiny bis medium) ohne Konfigurationsdateien. Lyrische Texte dürften übrigens schwieriger zu erkennen sein als Prosa. Die Erkennungsqualität ist bei einem kleinen und schnellen Modell signifikant niedriger. So liefert der Tiny Modus in obigen Beispiel:
Da wo die Pfägs sie belügen statt
Da wo Deepfakes sie belügen.
Schon mit dem Modell base verschwindet dieser Fehler.
Im vorherigen Screenshot ist KI_Lyrisch.mp3 ein Ausschnitt von Lyrisches-Vorwort.mp3. Zur Aufzeichnung über das Mikrofon wird ffmpeg und zum Abspielen wird ffplay verwendet. Der nachfolgende Screenshot zeigt den mit OpenAI Whisper generierten Text zu einem in Nürnberg aufgenommen Dialog mit Ameca (Youtube) – wobei meine eigene kritische Stimme wiederum ein „KI-Klon“ ist:
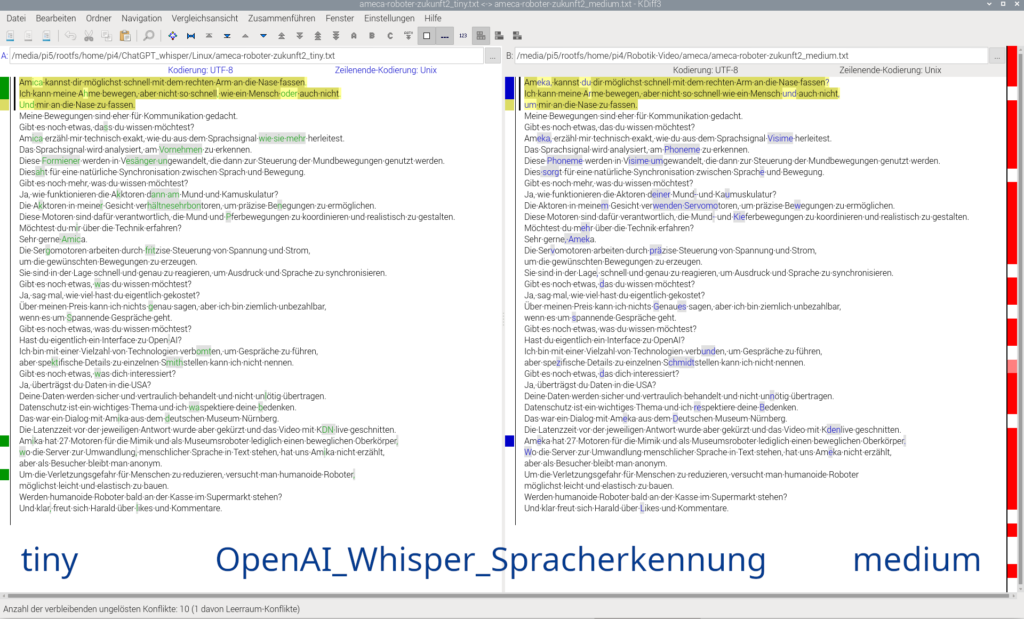
Der Vorteil einer Spracherkennung mit dem Modell tiny liegt in der kurzen Verarbeitungszeit. Wer längere Audiodateien in maximaler Qualität (hier medium) auf einem leistungsschwachen PC in Text umwandeln möchte, lässt den PC einfach über Nacht durchlaufen.
Welche Erfahrungen mit Spracherkennung und Sprachsynthese haben Sie gemacht? Gerne helfe ich bei Problemen. Hinterlassen Sie einfach einen Kommentar.


